The SQL INNER JOIN keyword returns rows when there is at least one match in both tables. Relational databases are often normalized to eliminate duplication of information when objects may have one-to-many relationships.
For example, a Department may be associated with many different Employees. Joining two tables effectively combines information from both tables to avoid duplication of data in either table.
Employees Table
employeeID | employeeName |
|---|---|
| 1000 | John Smith |
| 1001 | Fred White |
| 1002 | Jane Scott |
| 1003 | Samuel Williams |
Departments Table
deptName | employeeID |
|---|---|
| Sales | 1000 |
| HR | 1002 |
| Accounting | 1003 |
| Operations | 1004 |
In this example, employeeID is a primary key in the table called “Employees”. You’ll notice that employeeID also exists in the “Departments” table but as a foreign key. Using SQL Join, we can combine these two tables into one when presenting the results of a query.
Design Example
In this example, using an inner join, we can build a query to display the department name and employee name even though neither table has this information on its own. The two tables are joined by the ’employeeID’ field. We can use the INNER JOIN to bind this data together.
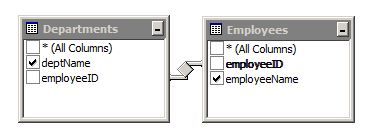
Syntax
SELECT tableName#.columnName#, etc...
FROM tableName1
INNER JOIN tableName2
ON tableName1.columnName# = tableName2.columnName#Example
List the departments and their assigned employees.
SELECT Departments.deptName, Employees.employeeName
FROM Employees
INNER JOIN Departments
ON Employees.employeeID = Departments.employeeIDResults
deptName | employeeName |
|---|---|
| Sales | John Smith |
| HR | Jane Scott |
| Accounting | Samuel Williams |
You should immediately notice that ‘Operations’ from the Department table and ‘Fred White’ from the Employees table are not included in the results. This is because there is there are no employees assigned to Operations, and Fred White is not assigned to a valid department ID.
If there are rows in “Departments” that do not have matches in “Employees” and vice versa, those rows will not be listed.











